마커 클러스터링
한 화면에 대량의 마커가 노출되면 성능이 저하될 뿐만 아니라 여러 마커가 겹쳐 나타나므로 시인성이 떨어집니다. 마커의 겹침 처리 기능을 사용하면 시인성을 일부 향상시킬 수 있으나 겹침 처리로 인해 가려진 마커의 정보를 알 수 없으며, 성능도 여전히 저하됩니다. 마커 클러스터링 기능을 이용하면 카메라의 줌 레벨에 따라 근접한 마커를 클러스터링해 성능과 시인성을 모두 향상시킬 수 있습니다.
기본적인 사용법
키 정의
마커 클러스터링 기능을 이용하려면 먼저 데이터의 키를 의미하는 ClusteringKey 인터페이스를 구현한 클래스를 정의해야 합니다. ClusteringKey 인터페이스는 데이터의 좌표뿐만 아니라 두 데이터가 동일한지를 정의합니다. 따라서 이 인터페이스를 구현하는 클래스는 equals() 및 hashCode()도 구현하는 것이 권장됩니다.
다음은 ClusteringKey를 구현하는 클래스를 정의하는 예제입니다.
class ItemKey implements ClusteringKey {
private final int id;
@NonNull
private final LatLng position;
public ItemKey(int id, @NonNull LatLng position) {
this.id = id;
this.position = position;
}
public int getId() {
return id;
}
@Override
@NonNull
public LatLng getPosition() {
return position;
}
@Override
public boolean equals(Object o) {
if (this == o)
return true;
if (o == null || getClass() != o.getClass())
return false;
ItemKey itemKey = (ItemKey)o;
return id == itemKey.id;
}
@Override
public int hashCode() {
return id;
}
}
Java
class ItemKey implements ClusteringKey {
private final int id;
@NonNull
private final LatLng position;
public ItemKey(int id, @NonNull LatLng position) {
this.id = id;
this.position = position;
}
public int getId() {
return id;
}
@Override
@NonNull
public LatLng getPosition() {
return position;
}
@Override
public boolean equals(Object o) {
if (this == o)
return true;
if (o == null || getClass() != o.getClass())
return false;
ItemKey itemKey = (ItemKey)o;
return id == itemKey.id;
}
@Override
public int hashCode() {
return id;
}
}
Kotlin
class ItemKey(val id: Int, private val position: LatLng) : ClusteringKey {
override fun getPosition() = position
override fun equals(other: Any?): Boolean {
if (this === other) return true
if (other == null || javaClass != other.javaClass) return false
val itemKey = other as ItemKey
return id == itemKey.id
}
override fun hashCode() = id
}
클러스터러 생성
실제 클러스터링 동작은 Clusterer 객체가 수행합니다. Clusterer 클래스의 인스턴스는 직접 생성할 수 없고 Clusterer.Builder를 사용해야 합니다. Clusterer.Builder는 데이터의 키를 의미하는 타입 파라미터를 요구하므로 앞서 정의한 클래스를 지정해야 합니다. 이후 build() 메서드를 호출하면 Clusterer 객체가 만들어집니다.
다음은 Clusterer 객체를 생성하는 예제입니다.
Clusterer<ItemKey> clusterer = new Clusterer.Builder<ItemKey>().build();
Java
Clusterer<ItemKey> clusterer = new Clusterer.Builder<ItemKey>().build();
Kotlin
val clusterer: Clusterer<ItemKey> = Clusterer.Builder<ItemKey>().build()
데이터 추가
마커 데이터를 추가하려면 생성한 Clusterer 객체의 add() 메서드를 호출해야 합니다. 데이터에는 키와 별도로 태그를 지정할 수 있으며, 필요치 않을 경우 null을 지정할 수 있습니다.
다음은 클러스터러에 데이터를 추가하는 예제입니다.
clusterer.add(new ItemKey(1, new LatLng(37.372, 127.113)), null);
clusterer.add(new ItemKey(2, new LatLng(37.366, 127.106)), null);
clusterer.add(new ItemKey(3, new LatLng(37.365, 127.157)), null);
clusterer.add(new ItemKey(4, new LatLng(37.361, 127.105)), null);
clusterer.add(new ItemKey(5, new LatLng(37.368, 127.110)), null);
clusterer.add(new ItemKey(6, new LatLng(37.360, 127.106)), null);
clusterer.add(new ItemKey(7, new LatLng(37.363, 127.111)), null);
Java
clusterer.add(new ItemKey(1, new LatLng(37.372, 127.113)), null);
clusterer.add(new ItemKey(2, new LatLng(37.366, 127.106)), null);
clusterer.add(new ItemKey(3, new LatLng(37.365, 127.157)), null);
clusterer.add(new ItemKey(4, new LatLng(37.361, 127.105)), null);
clusterer.add(new ItemKey(5, new LatLng(37.368, 127.110)), null);
clusterer.add(new ItemKey(6, new LatLng(37.360, 127.106)), null);
clusterer.add(new ItemKey(7, new LatLng(37.363, 127.111)), null);
Kotlin
clusterer.add(ItemKey(1, LatLng(37.372, 127.113)), null)
clusterer.add(ItemKey(2, LatLng(37.366, 127.106)), null)
clusterer.add(ItemKey(3, LatLng(37.365, 127.157)), null)
clusterer.add(ItemKey(4, LatLng(37.361, 127.105)), null)
clusterer.add(ItemKey(5, LatLng(37.368, 127.110)), null)
clusterer.add(ItemKey(6, LatLng(37.360, 127.106)), null)
clusterer.add(ItemKey(7, LatLng(37.363, 127.111)), null)
데이터를 추가할 때는 add() 메서드를 여러 번 호출하기보다 addAll() 메서드를 한 번만 호출하면 성능이 향상됩니다.
다음은 addAll()로 데이터를 추가하는 예제입니다.
Map<ItemKey, Object> keyTagMap = Map.of(
new ItemKey(1, new LatLng(37.372, 127.113)), null,
new ItemKey(2, new LatLng(37.366, 127.106)), null,
new ItemKey(3, new LatLng(37.365, 127.157)), null,
new ItemKey(4, new LatLng(37.361, 127.105)), null,
new ItemKey(5, new LatLng(37.368, 127.110)), null,
new ItemKey(6, new LatLng(37.360, 127.106)), null,
new ItemKey(7, new LatLng(37.363, 127.111)), null
);
clusterer.addAll(keyTagMap);
Java
Map<ItemKey, Object> keyTagMap = Map.of(
new ItemKey(1, new LatLng(37.372, 127.113)), null,
new ItemKey(2, new LatLng(37.366, 127.106)), null,
new ItemKey(3, new LatLng(37.365, 127.157)), null,
new ItemKey(4, new LatLng(37.361, 127.105)), null,
new ItemKey(5, new LatLng(37.368, 127.110)), null,
new ItemKey(6, new LatLng(37.360, 127.106)), null,
new ItemKey(7, new LatLng(37.363, 127.111)), null
);
clusterer.addAll(keyTagMap);
Kotlin
val keyTagMap = mapOf(
ItemKey(1, LatLng(37.372, 127.113)) to null,
ItemKey(2, LatLng(37.366, 127.106)) to null,
ItemKey(3, LatLng(37.365, 127.157)) to null,
ItemKey(4, LatLng(37.361, 127.105)) to null,
ItemKey(5, LatLng(37.368, 127.110)) to null,
ItemKey(6, LatLng(37.360, 127.106)) to null,
ItemKey(7, LatLng(37.363, 127.111)) to null
)
clusterer.addAll(keyTagMap)
지도 객체 지정
Clusterer 객체의 map 속성에 지도 객체를 지정하면 카메라의 줌 레벨에 따라 자동으로 클러스터링된 마커가 나타나며, 클러스터링된 마커를 클릭하면 클러스터가 펼쳐지는 최소 줌 레벨로 확대됩니다.
다음은 클러스터러에 지도 객체를 지정하는 예제입니다.
clusterer.setMap(naverMap);
Java
clusterer.setMap(naverMap);
Kotlin
clusterer.map = naverMap
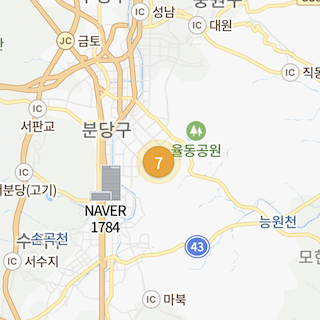
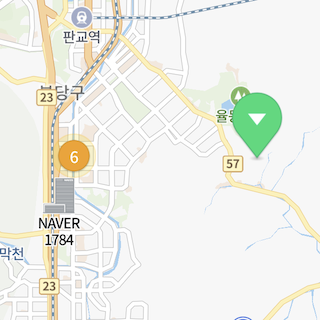
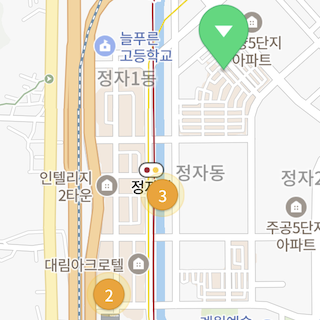
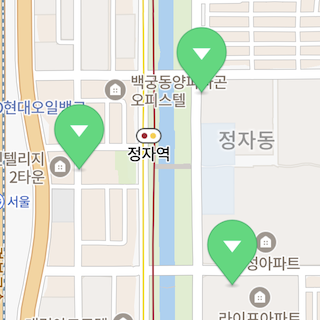
옵션 사용
Clusterer.Builder의 메서드를 호출해 클러스터링할 거리, 최소/최대 줌 레벨, 애니메이션 여부, 클러스터/단말 마커 커스터마이징 등 다양한 클러스터링 옵션을 지정할 수 있습니다.
클러스터링 거리
screenDistance() 메서드를 호출해 클러스터링할 기준 거리를 DP 단위로 지정할 수 있습니다. 클러스터에 추가된 두 데이터의 화면상 거리가 기준 거리보다 가깝다면 클러스터링되어 하나의 마커로 나타납니다.
다음은 클러스터러의 기준 거리를 20DP로 지정하는 예제입니다.
builder.screenDistance(20);
Java
builder.screenDistance(20);
Kotlin
builder.screenDistance(20.0)
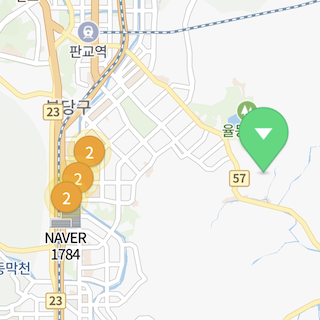
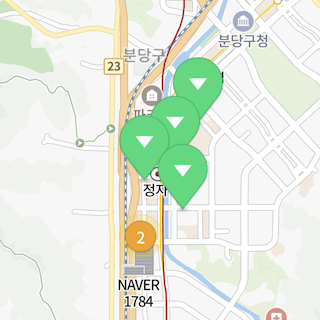
최소 및 최대 줌 레벨
minZoom() 및 maxZoom() 메서드를 호출해 클러스터링할 최소 및 최대 줌 레벨을 제한할 수 있습니다. 카메라의 줌 레벨이 최소 줌 레벨보다 낮거나 최대 줌 레벨보다 높다면 두 데이터가 화면상 기준 거리보다 가깝더라도 클러스터링되지 않습니다. 예를 들어, 클러스터링할 최소 줌 레벨이 4이고 최대 줌 레벨이 16이라면, 카메라의 줌 레벨을 3 이하로 축소하더라도 4레벨의 클러스터가 더 이상 클러스터링되지 않고 그대로 유지되며, 17 이상으로 확대하면 모든 데이터가 클러스터링되지 않고 낱개로 나타납니다.
다음은 클러스터러의 최소 레벨을 4, 최대 레벨을 16으로 지정하는 예제입니다.
builder.minZoom(4).maxZoom(16);
Java
builder.minZoom(4).maxZoom(16);
Kotlin
builder.minZoom(4.0).maxZoom(16.0)
확대/축소 애니메이션
animate() 메서드를 호출해 카메라 확대/축소시 클러스터가 펼쳐지는/합쳐지는 애니메이션을 적용할지 여부를 지정할 수 있습니다.
다음은 애니메이션을 적용하지 않도록 지정하는 예제입니다.
마커 커스터마이징
clusterMarkerUpdater() 및 leafMarkerUpdater() 메서드를 호출해 클러스터와 단말(leaf) 마커를 커스터마이징할 수 있습니다.
클러스터 마커를 커스터마이징하려면 clusterMarkerUpdater() 메서드를 호출해 ClusterMarkerUpdater 인스턴스를 지정해야 합니다. 클러스터 마커가 지도에 나타날 때마다 updateClusterMarker() 메서드가 호출되며, 파라미터로 ClusterMarkerInfo와 이를 표현할 마커 객체가 전달됩니다. ClusterMarkerInfo에는 클러스터의 크기, 노출되는 최소/최대 줌 레벨, 태그 등 클러스터 마커의 정보가 포함되어 있으므로 필요한 정보를 마커 객체의 속성에 반영하면 지도 화면에도 반영됩니다. 기본값인 DefaultClusterMarkerUpdater를 사용하면 클러스터의 크기를 캡션으로 노출하고 클러스터 클릭 시 클러스터가 펼쳐지는 최소 줌 레벨로 확대하는 기능 등을 이용할 수 있으므로 이를 상속받아 필요한 부분만 커스터마이징할 수도 있습니다.
단말 마커를 커스터마이징하려면 leafMarkerUpdater() 메서드를 호출해 LeafMarkerUpdater 인스턴스를 지정해야 합니다. 단말 마커가 지도에 나타날 때마다 updateLeafMarker() 메서드가 호출되며, 파라미터로 LeafMarkerInfo와 이를 표현할 마커 객체가 전달됩니다. LeafMarkerInfo에는 데이터가 노출되는 최소/최대 줌 레벨, 태그 등 단말 마커의 정보가 포함되어 있으므로 필요한 정보를 마커 객체의 속성에 반영하면 지도 화면에도 반영됩니다. 기본값인 DefaultLeafMarkerUpdater를 상속받아 필요한 부분만 커스터마이징할 수도 있습니다.
한편 클러스터러는 화면에 나타나야 하는 클러스터 및 단말 데이터만을 마커로 만들어 동적으로 지도에 추가/제거하며, 제거된 마커 객체는 기본적으로 재사용됩니다. 때문에 updateClusterMarker(), updateLeafMarker() 메서드로 전달되는 마커 객체에는 이전 데이터의 속성이 여전히 반영되어 있을 수 있습니다. 따라서 마커를 커스터마이징하고자 하는 경우 필요한 속성을 빠짐없이 덮어씌워야 합니다.
다음은 클러스터의 크기 및 데이터의 ID에 따라 마커 아이콘을 변경하고, 단말 마커를 클릭했을 때 클러스터러에서 제거하도록 지정하는 예제입니다.
OverlayImage[] icons = { MarkerIcons.BLUE, MarkerIcons.GREEN, MarkerIcons.RED, MarkerIcons.YELLOW };
builder.clusterMarkerUpdater(new DefaultClusterMarkerUpdater() {
@Override
public void updateClusterMarker(@NonNull ClusterMarkerInfo info, @NonNull Marker marker) {
super.updateClusterMarker(info, marker);
if (info.getSize() < 3) {
marker.setIcon(MarkerIcons.CLUSTER_LOW_DENSITY);
} else {
marker.setIcon(MarkerIcons.CLUSTER_MEDIUM_DENSITY);
}
}
}).leafMarkerUpdater(new DefaultLeafMarkerUpdater() {
@Override
public void updateLeafMarker(@NonNull LeafMarkerInfo info, @NonNull Marker marker) {
super.updateLeafMarker(info, marker);
ItemKey key = (ItemKey)info.getKey();
marker.setIcon(icons[key.id % icons.length]);
marker.setOnClickListener(o -> {
clusterer.remove(key);
return true;
});
}
})
Java
OverlayImage[] icons = { MarkerIcons.BLUE, MarkerIcons.GREEN, MarkerIcons.RED, MarkerIcons.YELLOW };
builder.clusterMarkerUpdater(new DefaultClusterMarkerUpdater() {
@Override
public void updateClusterMarker(@NonNull ClusterMarkerInfo info, @NonNull Marker marker) {
super.updateClusterMarker(info, marker);
if (info.getSize() < 3) {
marker.setIcon(MarkerIcons.CLUSTER_LOW_DENSITY);
} else {
marker.setIcon(MarkerIcons.CLUSTER_MEDIUM_DENSITY);
}
}
}).leafMarkerUpdater(new DefaultLeafMarkerUpdater() {
@Override
public void updateLeafMarker(@NonNull LeafMarkerInfo info, @NonNull Marker marker) {
super.updateLeafMarker(info, marker);
ItemKey key = (ItemKey)info.getKey();
marker.setIcon(icons[key.id % icons.length]);
marker.setOnClickListener(o -> {
clusterer.remove(key);
return true;
});
}
})
Kotlin
val icons = arrayOf(MarkerIcons.BLUE, MarkerIcons.GREEN, MarkerIcons.RED, MarkerIcons.YELLOW)
builder.clusterMarkerUpdater(object : DefaultClusterMarkerUpdater() {
override fun updateClusterMarker(info: ClusterMarkerInfo, marker: Marker) {
super.updateClusterMarker(info, marker)
marker.icon = if (info.size < 3) {
MarkerIcons.CLUSTER_LOW_DENSITY
} else {
MarkerIcons.CLUSTER_MEDIUM_DENSITY
}
}
}).leafMarkerUpdater(object : DefaultLeafMarkerUpdater() {
override fun updateLeafMarker(info: LeafMarkerInfo, marker: Marker) {
super.updateLeafMarker(info, marker)
val key = info.key as ItemKey
marker.icon = icons[key.id % icons.size]
marker.onClickListener = Overlay.OnClickListener {
clusterer.remove(key)
true
}
}
})
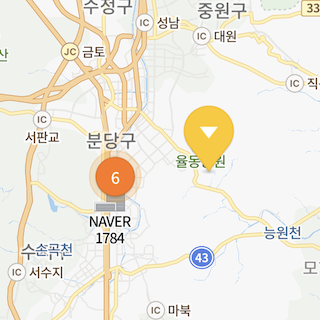
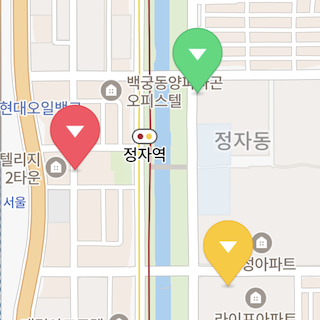
복잡한 전략 사용
Clusterer.Builder 대신 Clusterer.ComplexBuilder를 사용하면 화면상 거리가 아닌 다른 기준으로 데이터를 클러스터링하는 등 복잡한 전략과 기능을 사용할 수 있습니다.
노드
네이버 지도 SDK의 마커 클러스터링 기능은 hierarchical agglomerative clustering 알고리즘에 기반합니다. 즉, 클러스터러의 최대 줌 레벨부터 인접 데이터를 클러스터링하여, 최소 줌 레벨까지 바텀-업 방식으로 트리를 구성하며 클러스터링합니다. 따라서 트리에서 자식이 있는 노드는 클러스터, 단말 노드는 데이터가 됩니다.
각 노드는 Node 클래스로 표현되며, 클러스터와 단말 노드는 각각 Node의 하위 클래스인 Cluster와 Leaf로 표현됩니다.
노드를 이용해 공통적으로 좌표, 태그, 자식 노드의 개수, 노출되어야 하는 최소/최대 줌 레벨 속성을 가져올 수 있으며, 이에 더해 클러스터 노드는 자식 노드의 목록에, 단말 노드는 데이터의 키에 접근할 수 있습니다.
기준 거리 전략 및 거리 측정 전략
thresholdStrategy() 및 distanceStrategy() 메서드를 호출해 특정 줌 레벨에서 두 노드를 클러스터링할지에 대한 전략을 지정할 수 있습니다.
thresholdStrategy로 지정하는 ThresholdStrategy는 특정 줌 레벨에서 두 노드를 클러스터링할 기준 거리를 구하는 전략에 대한 인터페이스이며, distanceStrategy로 지정하는 DistanceStrategy는 특정 줌 레벨에서 두 노드간의 거리를 측정하는 전략에 대한 인터페이스입니다.
즉, 두 노드 node1과 node2가 있을 때, zoom 줌 레벨에서 DistanceStrategy.getDistance(node1, node2, zoom)가 ThresholdStrategy.getThreshold(zoom)보다 작거나 같다면 node1과 node2는 클러스터링됩니다. 이를 이용하면 줌 레벨에 따라 거리 기준을 달리하거나 화면상 거리와 무관하게 클러스터링 전략을 지정할 수 있습니다.
다음은 9레벨 이하에서는 무조건 클러스터링, 10~13레벨에서는 태그가 동일할 때 클러스터링, 14레벨 이상에서는 화면상 거리가 70 미만일 때 클러스터링하도록 전략을 지정하는 예제입니다.
complexBuilder.thresholdStrategy(zoom -> {
if (zoom <= 11) {
return 0;
} else {
return 70;
}
}).distanceStrategy(new DistanceStrategy() {
private final DistanceStrategy defaultDistanceStrategy = new DefaultDistanceStrategy();
@Override
public double getDistance(int zoom, @NonNull Node node1, @NonNull Node node2) {
if (zoom <= 9) {
return -1;
} else if (zoom <= 13) {
if (Objects.equals(node1.getTag(), node2.getTag())) {
return -1;
} else {
return 1;
}
} else {
return defaultDistanceStrategy.getDistance(zoom, node1, node2);
}
});
Java
complexBuilder.thresholdStrategy(zoom -> {
if (zoom <= 11) {
return 0;
} else {
return 70;
}
}).distanceStrategy(new DistanceStrategy() {
private final DistanceStrategy defaultDistanceStrategy = new DefaultDistanceStrategy();
@Override
public double getDistance(int zoom, @NonNull Node node1, @NonNull Node node2) {
if (zoom <= 9) {
return -1;
} else if (zoom <= 13) {
if (Objects.equals(node1.getTag(), node2.getTag())) {
return -1;
} else {
return 1;
}
} else {
return defaultDistanceStrategy.getDistance(zoom, node1, node2);
}
});
Kotlin
complexBuilder.thresholdStrategy { zoom ->
if (zoom <= 11) {
0.0
} else {
70.0
}
}
.distanceStrategy(object : DistanceStrategy {
private val defaultDistanceStrategy = DefaultDistanceStrategy()
override fun getDistance(zoom: Int, node1: Node, node2: Node): Double {
return when {
zoom <= 9 -> -1.0
zoom <= 13 ->
if (node1.tag == node2.tag) {
-1.0
} else {
1.0
}
else -> defaultDistanceStrategy.getDistance(zoom, node1, node2)
}
}
})
최대 화면 거리 제한
모든 노드에 대해 모든 인접 노드를 대상으로 클러스터링을 시도하면 시간복잡도가 기하급수적으로 증가하여 성능에 큰 악영향을 미칩니다. 때문에 화면상 거리를 기준으로 삼아 후보 노드에 대한 탐색 공간을 제한할 수 있습니다.
maxScreenDistance() 메서드를 호출해 클러스터링할 최대 화면 거리를 지정할 수 있습니다. 즉, 두 노드 node1과 node2가 있을 때, zoom 줌 레벨에서 두 노드의 화면상 거리가 이 값보다 크다면, DistanceStrategy.getDistance(node1, node2, zoom)가 ThresholdStrategy.getThreshold(zoom)보다 작거나 같더라도 node1과 node2는 클러스터링되지 않습니다.
따라서 ThresholdStrategy와 DistanceStrategy를 지정했다면 전략을 고려해 최적의 거리를 지정해야 합니다. 값을 너무 작게 지정하면 클러스터링되어야 하는 노드가 클러스터링되지 않을 수 있고, 너무 크게 지정하면 성능이 저하됩니다.
다음은 최대 화면 거리 제한을 100DP로 변경하는 예제입니다.
complexBuilder.maxScreenDistance(100);
Java
complexBuilder.maxScreenDistance(100);
Kotlin
complexBuilder.maxScreenDistance(100.0)
태그 병합 전략
단말 노드에는 Clusterer.add()로 지정한 키와 태그가 유지됩니다. 하지만 클러스터 노드는 여러 노드가 클러스터링되어 만들어진 것이므로 키를 가질 수 없으며, 태그 역시 자동으로 생성할 수 없습니다.
대신 tagMergeStrategy() 메서드를 호출해 자식 노드들의 태그를 병합해 클러스터 노드의 태그로 삼는 전략을 지정할 수 있습니다. 여러 노드가 하나의 클러스터로 클러스터링될 때마다 mergeTag() 메서드가 호출되며, 파라미터로 전달되는 Cluster의 children을 이용해 자식 노드를 순회할 수 있습니다. 자식 노드의 태그를 병합해 반환하면 반환한 값이 Cluster의 태그가 됩니다.
다음은 데이터의 태그가 정수일 때, 자식 노드의 정수를 모두 더해 부모 클러스터의 태그로 삼는 전략을 지정하는 예제입니다.
complexBuilder.tagMergeStrategy(cluster -> {
int sum = 0;
for (Node node : cluster.getChildren()) {
if (node.getTag() != null) {
sum += (int)node.getTag();
}
}
return sum;
});
Java
complexBuilder.tagMergeStrategy(cluster -> {
int sum = 0;
for (Node node : cluster.getChildren()) {
if (node.getTag() != null) {
sum += (int)node.getTag();
}
}
return sum;
});
Kotlin
complexBuilder.tagMergeStrategy { cluster ->
cluster.children.sumOf { it.tag as Int }
}
좌표 전략
단말 노드의 좌표는 Clusterer.add()로 지정한 키의 좌표입니다. 하지만 클러스터 노드는 여러 노드가 클러스터링되어 만들어진 것이므로 좌표를 계산해서 지정해야 합니다.
positioningStrategy() 메서드를 호출해 클러스터 노드의 좌표를 정하는 전략을 지정할 수 있습니다. 여러 노드가 하나의 클러스터로 클러스터링될 때마다 getPosition() 메서드가 호출되며, 파라미터로 전달되는 Cluster의 children을 이용해 자식 노드를 순회할 수 있습니다. 좌표 등 자식 노드의 정보를 이용해 WebMercatorCoord 좌표를 반환하면 반환한 값이 Cluster의 좌표가 됩니다.
다음은 무조건 첫 번째 자식 노드의 좌표를 클러스터 노드의 좌표로 삼는 전략을 지정하는 예제입니다.
complexBuilder.positioningStrategy(cluster -> cluster.getChildren().get(0).getCoord())
Java
complexBuilder.positioningStrategy(cluster -> cluster.getChildren().get(0).getCoord())
Kotlin
complexBuilder.positioningStrategy { clusterer -> clusterer.children.first().coord }
마커 관리
클러스터러는 화면에 포함되는 노드만을 마커로 변환해 노출합니다. 때문에 화면에 동시에 나타나는 마커의 개수를 효과적으로 제한할 수 있으며 재사용에도 유리합니다. 하지만 마커의 속성 중 변하지 않는 것이 있더라도 매번 덮어씌워줘야 하는 비효율이 발생합니다.
markerManager() 메서드를 호출해 마커를 관리하는 객체를 지정하면 마커를 직접 관리하여 비효율을 최소화할 수 있습니다. 마커 객체가 필요해지면 retainMarker() 메서드가, 불필요해지면 releaseMarker() 메서드가 호출되므로 ClusterMarkerUpdater와 LeafMarkerUpdater에서 관리하지 않는 속성은 여기서 공통 관리할 수 있습니다.
또한 기본 MarkerManager 구현체인 DefaultMarkerManager를 상속하여 createMarker() 메서드만 오버라이드할 수도 있습니다. 이렇게 하면 효율적인 마커 풀 및 객체 재사용 기능을 그대로 활용하면서 공통 속성만을 간편하게 관리할 수 있습니다.
다음은 DefaultMarkerManager를 상속하여 새로 생성되는 마커의 서브캡션 관련 속성만을 지정하는 예제입니다.
complexBuilder.markerManager(new DefaultMarkerManager() {
@NonNull
@Override
public Marker createMarker() {
Marker marker = super.createMarker();
marker.setSubCaptionTextSize(10f);
marker.setSubCaptionColor(Color.WHITE);
marker.setSubCaptionHaloColor(Color.TRANSPARENT);
return marker;
}
});
Java
complexBuilder.markerManager(new DefaultMarkerManager() {
@NonNull
@Override
public Marker createMarker() {
Marker marker = super.createMarker();
marker.setSubCaptionTextSize(10f);
marker.setSubCaptionColor(Color.WHITE);
marker.setSubCaptionHaloColor(Color.TRANSPARENT);
return marker;
}
});
Kotlin
complexBuilder.markerManager(object : DefaultMarkerManager() {
override fun createMarker() = super.createMarker().apply {
subCaptionTextSize = 10f
subCaptionColor = Color.WHITE
subCaptionHaloColor = Color.TRANSPARENT
}
})